Robust depth estimation across diverse scenarios — fog, night, underwater, animation, and high-resolution video.
Promotional video — zero-shot depth across diverse scenarios.
Robust depth estimation across diverse scenarios — fog, night, underwater, animation, and high-resolution video.
Monocular video depth estimation requires temporal consistency, geometric accuracy, and generalization across diverse scenarios — yet existing methods struggle to achieve all three simultaneously. Discriminative models excel at per-frame accuracy but suffer from temporal drift due to limited context windows, while generative methods improve consistency and generalization at the cost of extensive training data (10M+ samples) and lack of geometric precision.
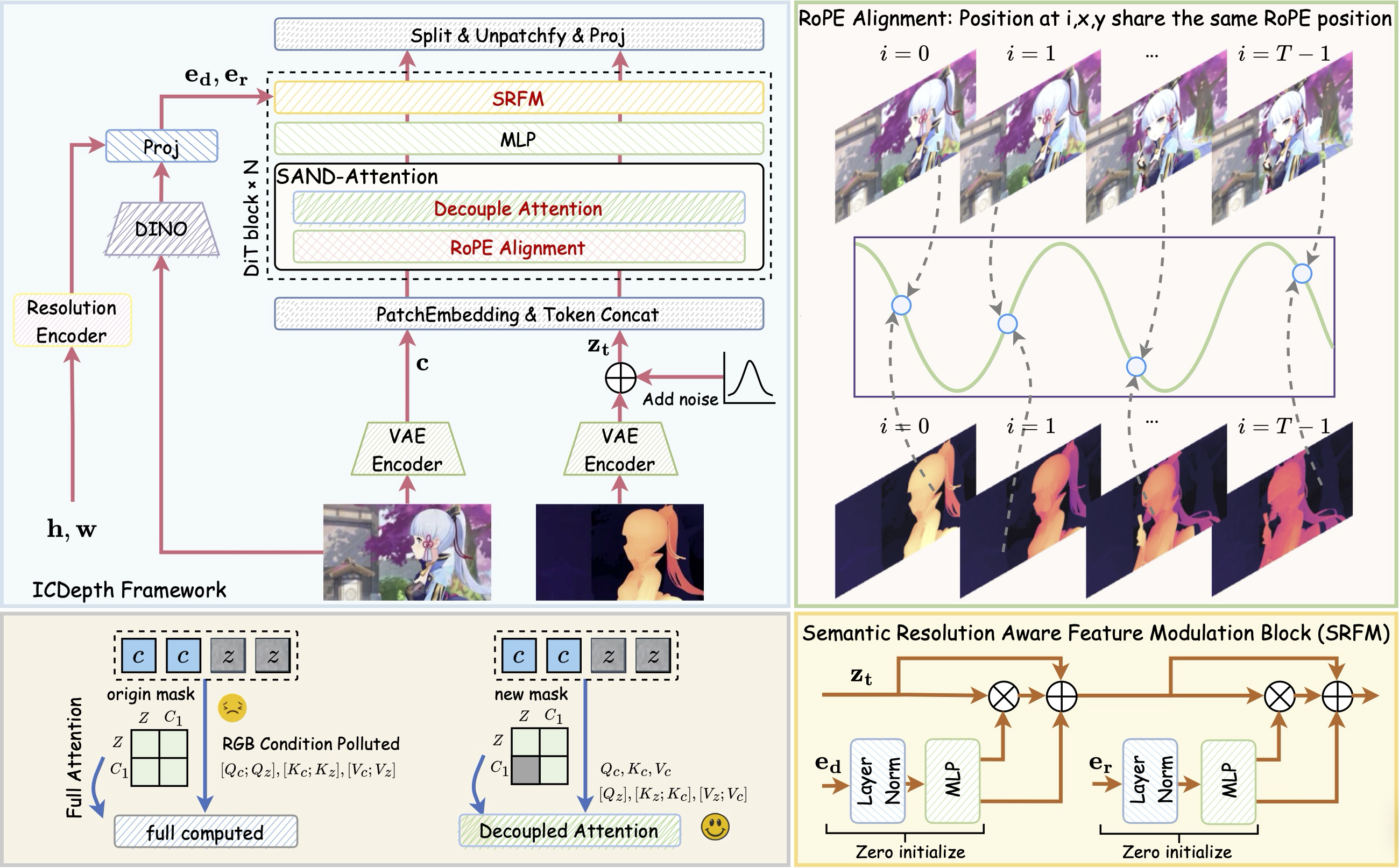
We introduce ICDepth, a framework that adapts pre-trained text-to-video diffusion transformers for video depth estimation via In-Context Conditioning (ICC), leveraging their rich spatial-temporal priors. To address key challenges in transferring ICC from generation to dense prediction, we propose:
ICDepth achieves state-of-the-art results on multiple benchmarks with remarkable data efficiency, trained on only 0.8M frames (6–13× less than competing generative methods), while demonstrating strong zero-shot generalization to diverse domains.
ICDepth builds upon the Wan 2.1 VDiT and treats RGB and depth as a unified token sequence processed by native attention.
Establishes precise spatial-temporal alignment between clean RGB conditions and noisy depth latents through Shared RoPE, and enforces Unidirectional Attention so noisy depth tokens can query clean RGB tokens while blocking the reverse flow.
Injects powerful external priors into the generative model by leveraging DINOv2 features for semantic understanding and Resolution Embeddings to support multi-scale inference up to 1080p.
Comparison against DepthCrafter, Depth Any Video, and Video Depth Anything. Click tabs to change scene type; use arrows to browse multiple cases per scene.
Table 1. Zero-shot video depth estimation on Sintel, ScanNet, KITTI, and Bonn. Red bold = best, underline = second best. Metrics follow the official DepthCrafter evaluation protocol.
| Method | Sintel (50 frames) |
ScanNet (90 frames) |
KITTI (110 frames) |
Bonn (110 frames) |
Venue | Data Size | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel ↓ | δ1 ↑ | AbsRel ↓ | δ1 ↑ | AbsRel ↓ | δ1 ↑ | AbsRel ↓ | δ1 ↑ | |||
| Depth Anything V2 | 0.403 | 0.547 | 0.123 | 0.852 | 0.102 | 0.910 | 0.084 | 0.947 | NeurIPS'24 | 62.62M |
| Video Depth Anything | 0.383 | 0.629 | 0.075 | 0.954 | 0.078 | 0.950 | 0.053 | 0.975 | CVPR'25 | 1.35M |
| ChronoDepth | 0.587 | 0.486 | 0.159 | 0.783 | 0.167 | 0.759 | 0.100 | 0.911 | CVPR'25 | — |
| DepthCrafter | 0.313 | 0.680 | 0.142 | 0.803 | 0.105 | 0.898 | 0.066 | 0.971 | CVPR'25 | 10.5M |
| Depth Any Video | 0.300 | 0.643 | 0.119 | 0.865 | 0.098 | 0.925 | 0.063 | 0.963 | ICLR'25 | 6M |
| ICDepth (Ours) | 0.250 | 0.749 | 0.076 | 0.952 | 0.061 | 0.968 | 0.053 | 0.979 | — | 0.8M |
Table 2. Component analysis on the Sintel dataset.
| Method Variant | AbsRel ↓ | RMSE ↓ | δ1 ↑ |
|---|---|---|---|
| Full model (Ours) | 0.250 | 5.155 | 0.749 |
| In-Context Conditioning (ICC) | |||
| Replace with channel concat | 0.367 | 5.956 | 0.654 |
| SAND-Attention | |||
| Replace with full attention | 0.413 | 6.078 | 0.443 |
| w/o RoPE Alignment | 0.410 | 5.999 | 0.450 |
| w/o Decoupled Attention | 0.262 | 5.196 | 0.710 |
| Semantic-Resolution Aware Feature Modulation (SRFM) | |||
| w/o SRFM | 0.306 | 6.325 | 0.696 |
| w/o DINOv2 features | 0.269 | 5.730 | 0.709 |
| w/o Resolution Embedding | 0.264 | 5.565 | 0.728 |
Visual comparison of ablation variants on KITTI.
@inproceedings{he2026icdepth,
title = {ICDepth: Taming Video Diffusion Models for Video Depth Estimation via In-Context Conditioning},
author = {He, Xuanhua and Xie, Jiaxin and Zheng, Mingzhe and Chen, Qifeng},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}